标签: 优质分享
- 作者帖子

zhudw游客bookget v1.0.2
[新增] 天一阁博物院古籍数字平台
[修改] 默认读取bookget本地目录下cookie.txt文件提示:
需要cookie.txt ,压缩包内置有。若不能下载,请手动修改cookie文件。
可以下载已扫描图像的书籍(包含需要到阅读室,不能下载无图的书籍)。
如果看到【Please try again later.[401 Unauthorized]】多试一两次就可以。
tigershuai游客又更新了,非常感谢。
光游客
zhudw游客@光 #81104
天一阁好像没有公开医类书籍。国医典藏3.0只开放了前30页图像。
爱好者游客请问天一阁的地址是什么?以前的http://www.tianyige.com.cn:8008打不开了
zhudw游客
墨雲游客@zhudw #81122
有公开医书,但但不多,因为无法进行资源筛选,所以搜索相当困难,只能一页页检查
zhudw游客@墨雲 #81141
测试搜索【本草】找到书号【善2375】可以下载。如果提示【温馨提示:暂无扫描数据】这种就不能下载了。
本草綱目五十二卷附圖三卷瀕湖脉學一卷脉訣攷證一卷奇經八脉攷一卷 https://gj.tianyige.com.cn/SearchPage/0fb94b1bdc0fb86a9c3b4b615116c658
光游客@zhudw #81122
谢谢!可惜了,国医典藏原来那么多经典医书,甘肃图书馆也多,都是不完整的!
墨雲游客@zhudw #81145
我知道没有数据就无资源,我想说的是必须一个个点进书目信息才能确认有没有资源,相当麻烦,又没有有资源的目录,或者筛选出只显示有资源的书目。
wd369游客@墨雲 #81167
在查询图书时有json 信息, 从其中的几项数值可以得知是否有扫描。
墨雲游客@zhudw #81145
对了天一阁下载这个能加多一个图片连接查重吗,因为很多书签的图片是重复的,而图片的实际地址也是一样的,而全部重复的图片都被下载了下来,而图片的实际网址也是一样的,
庄子游客請教一下套書没法设置只下其中某一册是吧?比如这本有20册,点着看了看地址都一样,谢谢!
江山無限游客@zhudw 请问,如果 天一阁 多册的如果中断下载,可否有简单继续的方法
庄子游客@江山無限 #81241
重下即可,会跳过已下载的
以正游客不懂就问,dezoomify-rs-zhudw这个软件是干啥用的?
墨雲游客@以正 #81267
应该就是那个拼图软件的修改版,更适应bookget吧
zhudw游客@庄子 #81232
我一直也感觉,对于多册书,分册下载是会比较好一些。有时候偷懒,就没去这样写。
天一阁的下载,增加了一个测试功能,请到百度盘的【测试版】目录去下载。
使用系统终端运行bookget,只要添加参数 -vol 2,即表示下载第2册。默认不填写,会下载所有册,并且一册一个目录单独存放。
命令如下:
.\bookget.exe -vol 2 "https://gj.tianyige.com.cn/SearchPage/aa13185a8fc77c6e186eccd185e95a47"
zhudw游客
庄子游客@zhudw #81313
有勞您修改完善了,主要是有些大套書相互間關係并不大,只需要其中小部分,非常感謝!
最初游客啥命令可以几本书一起下载
zhudw游客
yngwie游客@zhudw #81342
不知道zhudw老师是否可考虑在软件中,加入「江苏省珍贵古籍数字资源集成平台」(http://218.2.105.121/#/library)下载?感谢!受惠软件及平台甚多,借此致上谢意。
zhudw游客@yngwie #81372
江苏和云南、四川都是同一个软件系统。略作修改,已经支持了。请下载最新的1.0.3版试一下。
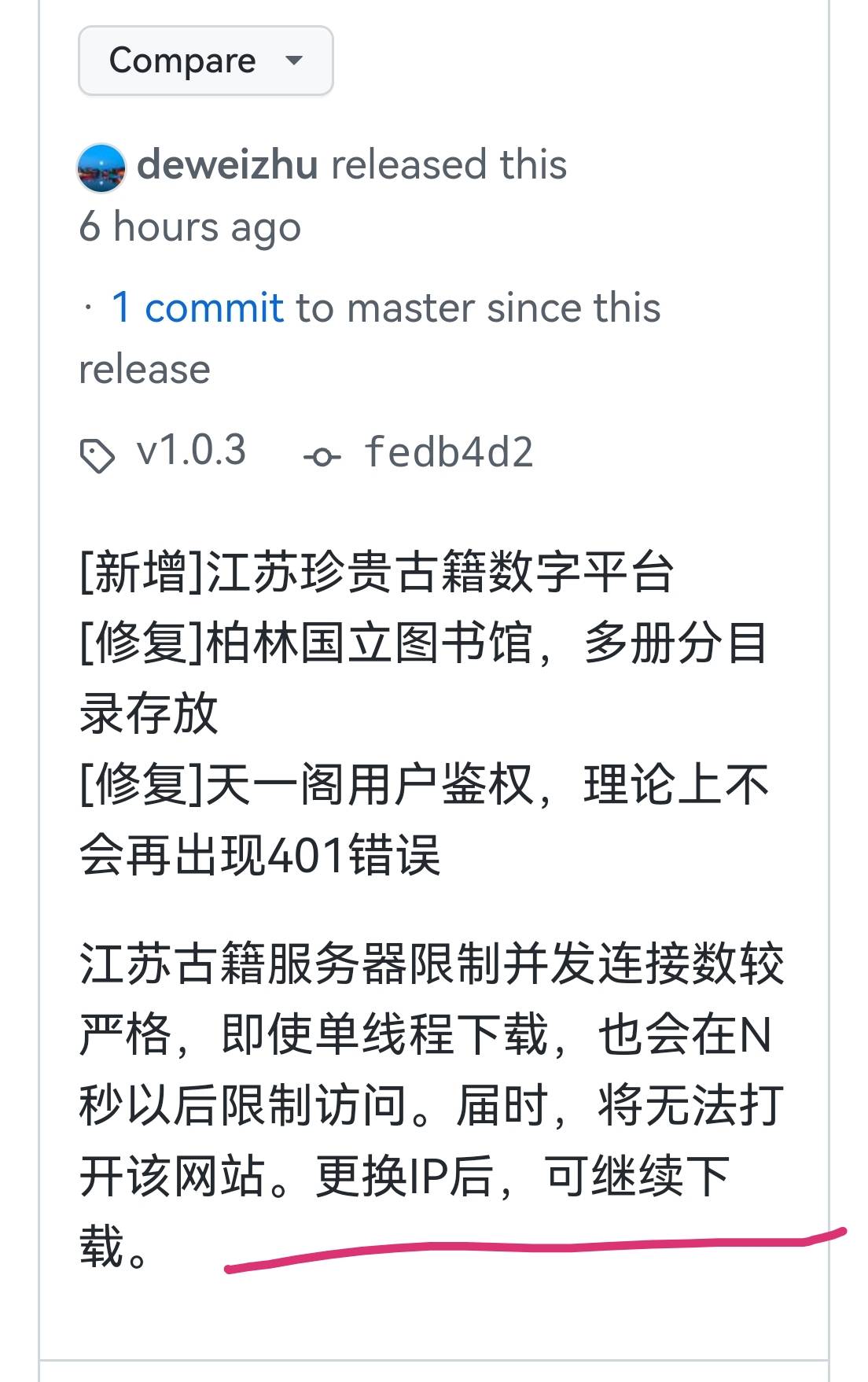
江苏古籍服务器限制并发连接数较严格,即使单线程下载,也会在N秒以后限制访问。届时,将无法打开该网站。更换IP后,可继续下载。
zhudw游客@未曾先生,如果看到。请帮忙更新一下,一楼的原帖。谢谢!
项目主页:http://github.com/deweizhu/bookget
此工具用于下载数字化古籍图书,目前支持约30~40个图书馆。
采用GPL-3.0开源协议,欢迎有开发能力的朋友二次修改、分发(前提是你遵守了GPL-3.0 license)。
最新下載地址:
github:https://github.com/deweizhu/bookget/releases
百度盘:https://pan.baidu.com/s/1RGvNEp3gDqB4z_r3SGwKmw?pwd=55uk
一般同步更新,推荐从github下载,它包含源代码、及说明文档。更新日志
bookget v1.0.3
[新增]江苏珍贵古籍数字平台
[修复]柏林国立图书馆,多册分目录存放
[修复]天一阁用户鉴权,理论上不会再出现401错误bookget v1.0.2
[新增] 天一阁博物院古籍数字平台
[修改] 默认读取bookget本地目录下cookie.txt文件bookget v1.0.1
[新增]四川数字古籍图书馆
[新增]云南数字古籍图书馆提示:
1、四川、云南、江苏古籍数字平台,需要使用 dezoomify-rs-zhudw 修改版。(无需单独下载,最新版已包含)
2、使用前,请先阅读项目主页上的说明文档。
道统游客你好 我想请问下 下载好了的文件名是需要手工重新命名的吗 想知道是不是自己弄错了

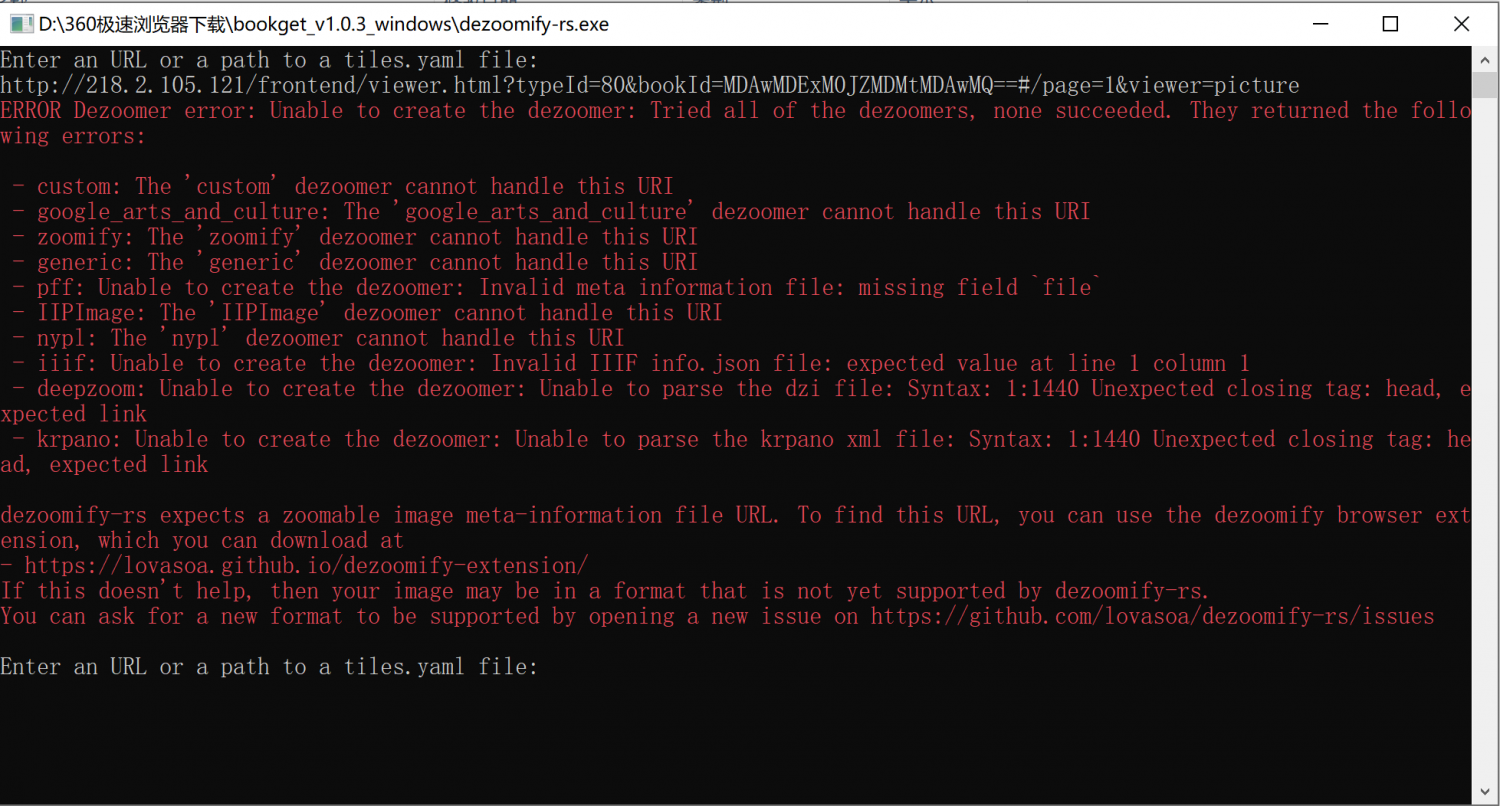
听雨游客请教大神,下载江苏省珍贵古籍数字资源集成平台的书出现这种情况怎么处理?
道统游客@zhudw #81477
谢谢 十分感谢 国图下载中
听雨游客
zhudw游客
Jenkins游客请教一下,cookie方式下载是否只适用于国会图书馆、familysearch 家谱网等4个网站?列表没有的图书馆是否不支持的?
zhudw游客@Jenkins #81484
只有 US 国会、family 家谱最需要 cookie ,其它的不太需要,用压缩包中的就可以。
列表中没有的,是不支持的。有一种情况除外:如果某网站使用的是 iiif 标准,虽然不在支持列表中,也可以下载。
zhudw游客@Jenkins #81484
补充说明:如果某网站的图片文件名是有规律的,0001、0002 这种每页递增,也可以批量下载。详见说明文档。
MEMORY游客感谢大神,许久未开电脑上网,新年第一眼看到这个贴,感谢感谢!
听雨游客@zhudw #81483
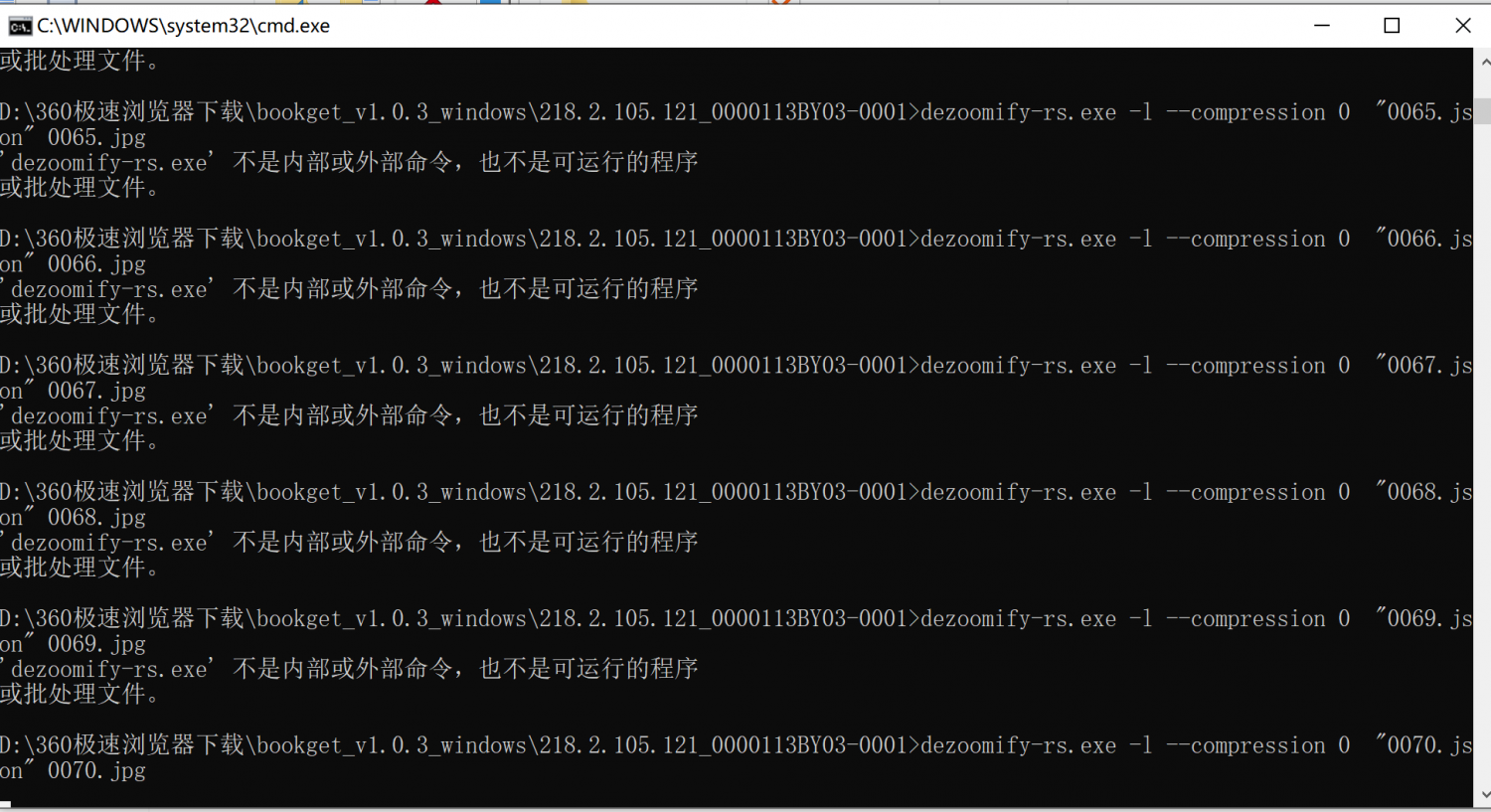
斗胆再问一下,设置了环境变量,下载了十几张图片后又出问题,不知哪里设置不对。
zhudw游客
zhudw游客@MEMORY #81489
我也是最近几日才上来,祝一切安好。
yngwie游客@zhudw #81412
非常感谢!!!
未曾管理员@zhudw #81417
感谢~我刚看到,已更新到主帖
轩辕十四游客@zhudw #81494
请教先生,book1.3下载资料后如何更改到指定路径文件夹?以及更改图片尺寸大小?
之前一直用这个习惯了,不知能否增加一个类似的参数值设置?
另请教天一阁,键盘Ctrl+C无法复制字体,只能鼠标右键-复制才行。。网上搜寻需要植入代码,小白能力有限, 还望先生赐教,感谢!
zhudw游客@轩辕十四 #81564
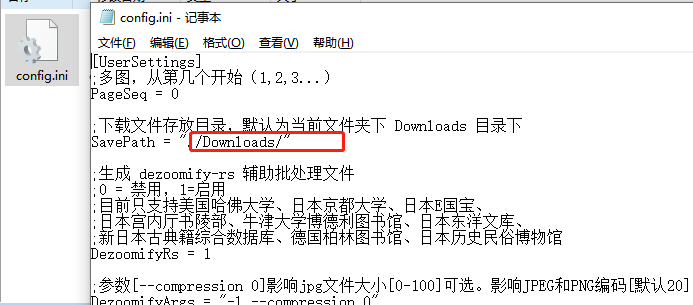
你试试0.2.6版(百度网盘里有旧版)。以下两个参数,可以改存放目录和iiif的图片大小。旧版不会更新了,源码都删除了。请用最新版。
SavaPath="D:\downloads" FullImageWidth = 7000
轩辕十四游客@zhudw #81573
好的,请问先生怎么将旧版的用在新版1.3里?是将“config.ini”整体放入1.3的文件夹里吗?
zhudw游客@轩辕十四 #81575
需要解释一下:
截止今天,最新版是1.0.3(不是1.3版),最后一个使用config.ini的版本是0.2.6。自0.2.7版以后,废弃了config.ini文件,改用命令行参数。不能把旧版的配置文件复制到新版中,不生效的。
上文你提到想解除浏览器右键锁定,可以试一下Edge浏览器扩展 Simple Allow Copy ,这个扩展可以解除大多数网站禁止右键的功能。具体方法你百度一下。
轩辕十四游客@zhudw #81577
感谢先生回复,抱歉把版本说错了,是1.0.3。
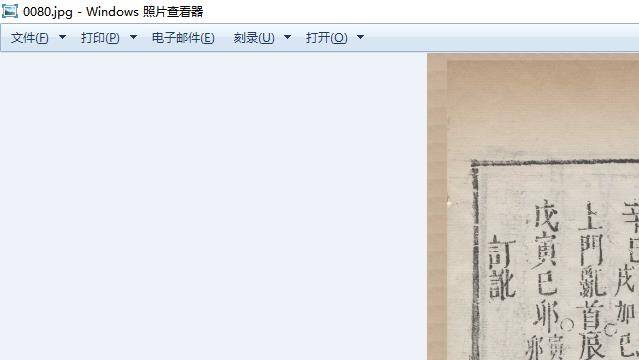
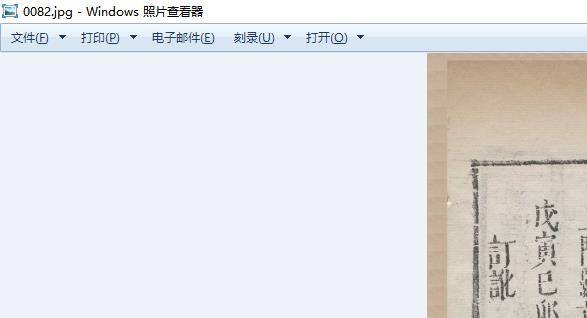
刚下载天一阁资料,发现有个小问题,就是比如大六壬不分卷
gj.tianyige.com.cn/Searc...a99bd9e100
第11册的图片相邻序号,内容都一样,如第64-65页的2页内容:
或80-82中的3页内容、或有跳页情况(第88张内容是56,下一页就90页57了):
劳烦先生帮忙看一下,感谢!
zhudw游客@轩辕十四 #81578
天一阁存在重复图片,错乱图片。应该是原本如此。需要手动算处理。bookget 暂时无法处理这类问题。
轩辕十四游客@zhudw #81583
好的,感谢先生回复!
tigershuai游客希望先生写一个该工具常用命令行参数说明,这样使用就更方便了。
zhudw游客@tigershuai #81628
常用的不多,github项目主页上有写。
每个人的需求不一样,我下载图书喜欢最大最高清的,不介意浪费硬盘空间和时间。而且喜欢jpg,又不喜欢png;喜欢jp2,又多于喜欢jpg。这其中人看个人的喜好决定怎么使用。
以我为例,最常用的就是:
bookget "https://..." #单图书下载 bookget -i urls.txt #批量图书下载 bookget -c cookie.txt #带cookie,自1.0.3起不需要了,默认会带这个 bookget -h #查看帮助
读者游客感谢一把 神器
- 作者帖子