标签: 优质分享
- 作者帖子

桐桐游客台图是下不了了吗,刚才试着下文件都是坏的
zhudw游客@桐桐 #88928
刚测试,失效了。不能下载了。
江南有雪游客很久没来了,一来就看到有如此惊喜,实是感激之至!@zhudw @未曾
zhudw游客bookget v1.1.3
[重写]台北古籍文献
[重写]美国国会图书馆,支持分册
[更改]香港中文大学改用webview生成cookie(仅Windows版有效)
[修复]familysearch
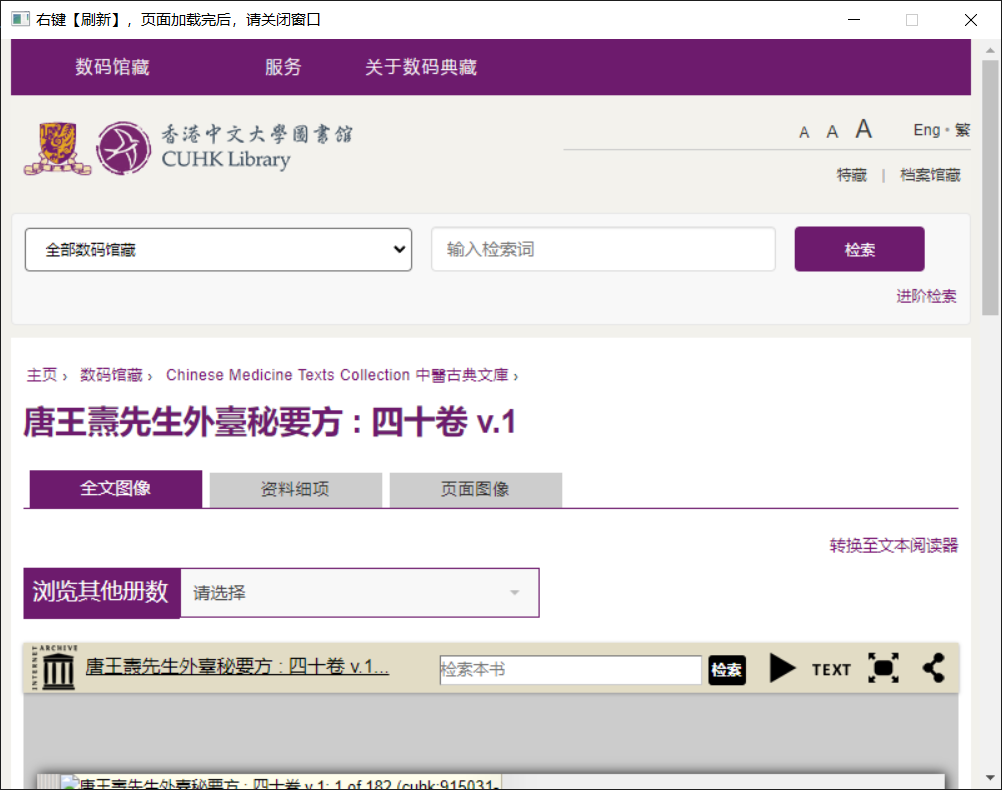
[修复]云南中医古籍部分图书如下图,香港中文在Windows电脑上会弹出一个窗口(可以右键刷新一下),关闭窗口后就可以开始下载了。下载过程中,cookie失效后会再次弹出窗口。下载完后会缺页(弹窗1次缺1页),需要重复下载一次(会跳过已经存在的文件,不要有心理负担,秒过)。

zhudw游客@江南有雪 #89001
欢迎回来
zuozuotingting游客@zhudw #89039
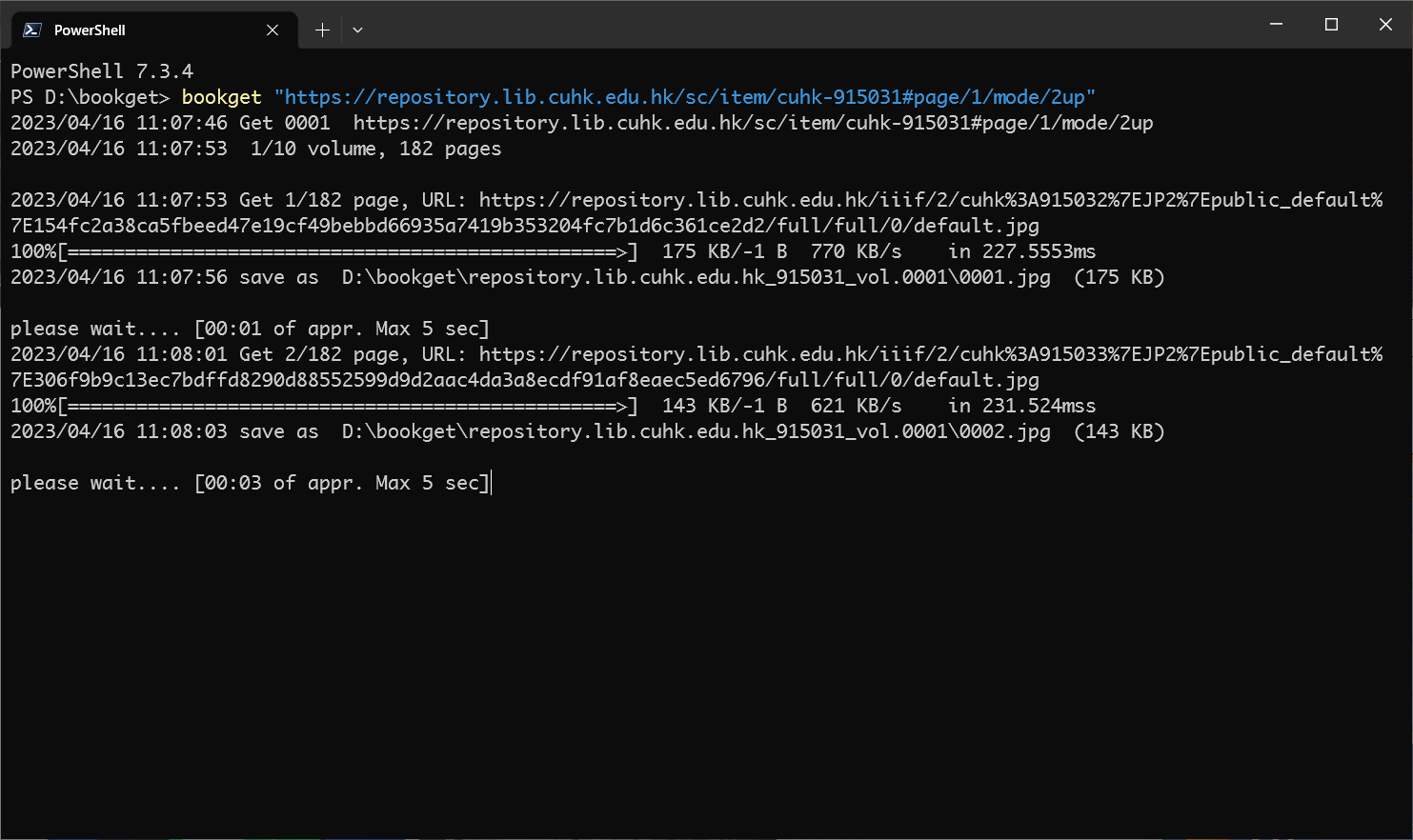
大老,好像-vol是用不了吗,还是我方法错了?我用以下那个命令,怎么始终从第一卷开始下载而不是从第3卷开始,请教下大神,用的是bookget_v1.1.2版本,谢谢了
bookget.exe -speed 10 -vol 3 "https://repository.lib.cuhk.edu.hk/en/item/cuhk-2489899#page/1/mode/2up"
zhudw游客
haha游客@zhudw #89064
1.1.3版是去掉台图的speed参数了吗,刚试了下了一本书,下载过快被封了
zhudw游客@haha #89073
再下一次1.1.3试试
书缘2022游客@zhudw #89076
辛苦zhudw大神一直无偿维护更新下载工具,太方便了!冒昧地问一下能否增加支持下国图的“前尘旧影”、“碑帖精华”板块,就是图片。
阿猫一条鱼游客@书缘2022 #89102
那个可以直接F12调出开发工具找到,或者浏览器安装一个图片下载助手(谷歌系推荐:图片助手(ImageAssistant))也非常方便的~
镜像之美游客@zhudw #89076
大侠好!辛苦了!可惜我这里台北古籍也是这样,下载不了,不知如何解决?
镜像之美游客@zhudw #89076
谢谢大侠!没有删除旧版造成,已解决!
兰亭幽梦游客
zhudw游客@兰亭幽梦 #89152
试了一下,用dezoomify-rs软件无法下载。因此bookget也无法下载,拼图是调dezoomify-rs进行工作的。
兰亭幽梦游客@zhudw #89159
非常感谢,我明白了,
tigershuai游客@兰亭幽梦 #89166
可以到https://github.com/lovasoa/dezoomify-rs/issues,发帖向dezoomify-rs作者询问这类图的下载方法
zhudw游客@兰亭幽梦 #89166
@tigershuai #89211
不是dezoomify-rs的问题,是这个si.edu的网站对iiif标准支持的不友好。
可以重新下载一次1.1.3版,试一下以下URL:
https://www.si.edu/object/thatched-hut-dreaming-immortal:fsg_F1939.60 https://iiif.si.edu/mirador/?manifest=https://ids.si.edu/ids/manifest/FS-F1939.60_Stitched https://ids.si.edu/ids/manifest/FS-F1939.60_Stitched
轩辕十四游客@zhudw #89236
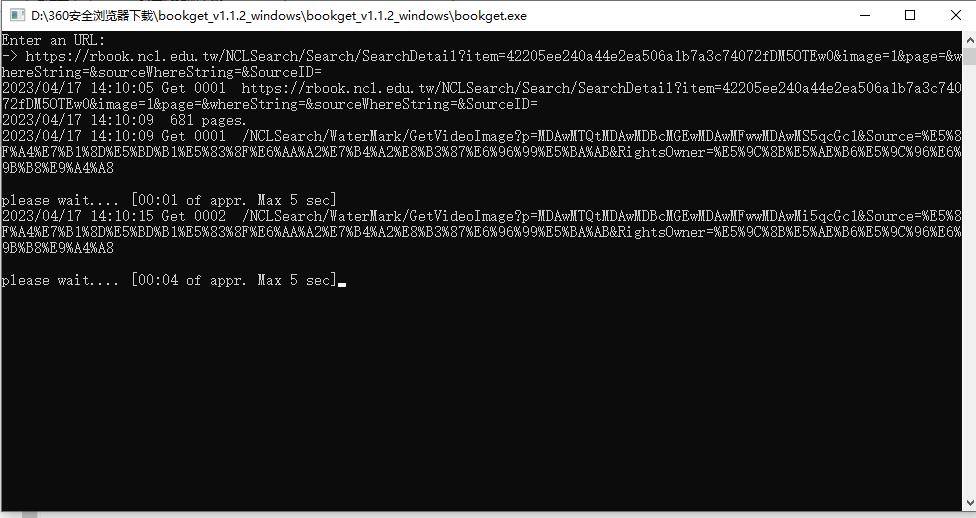
老师好,请教您关于“urls.txt”使用方法,批量下载下面四个链接,我建立urls.txt里了,终端输入对应E盘,然后输入wiki里的批量命令
,还是无法下载,请教下“urls.txt”正确的使用方法。。(环境变量已新建E)babel.hathitrust.org/cgi/p...#038;seq=1
babel.hathitrust.org/cgi/p...#038;seq=1
babel.hathitrust.org/cgi/p...#038;seq=1
babel.hathitrust.org/cgi/p...#038;seq=1
zhudw游客@轩辕十四 #89399
·、起一个简短一点的目录名字,不要层级那么深,好用一些。例如:E:\bookget
2、urls.txt 批量URL文件,可以和bookget.exe在同一个文件夹下,也可以在任意位置。
3、用你现在的环境变量,不作修改。只须把urls.txt移到E盘下,可以执行以下命令下载:
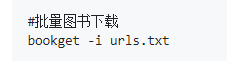
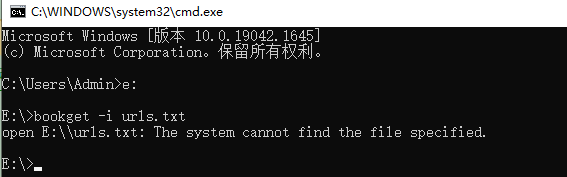
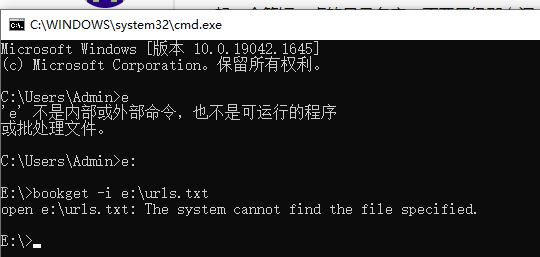
bookget -i e:\urls.txt
轩辕十四bookget -i E:urls.txt游客@zhudw #89424
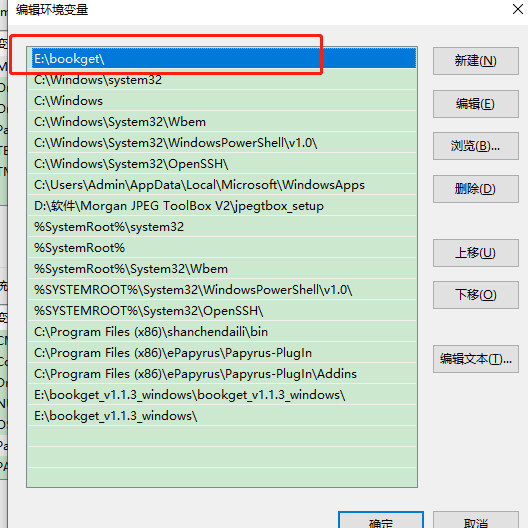
感谢老师回复,我已将1.1.3文件夹名称缩改为bookget,下一级就是如下图:
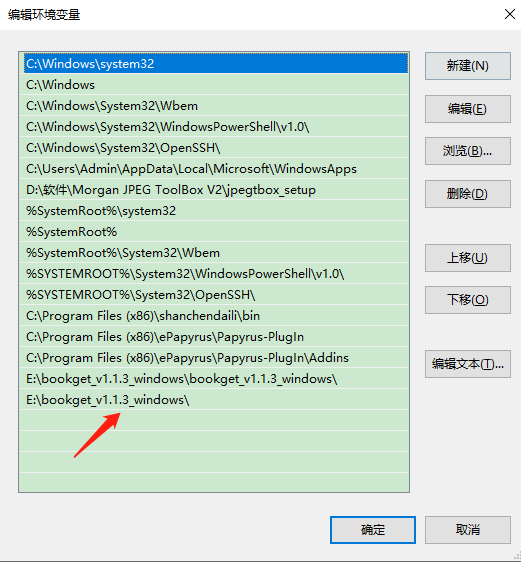
环境变量新建:
终端后输入:bookget -i e:\urls.txt 还是不行,如下图所示:请教下,具体哪里设置不对?
zhudw游客@zhudw #89424
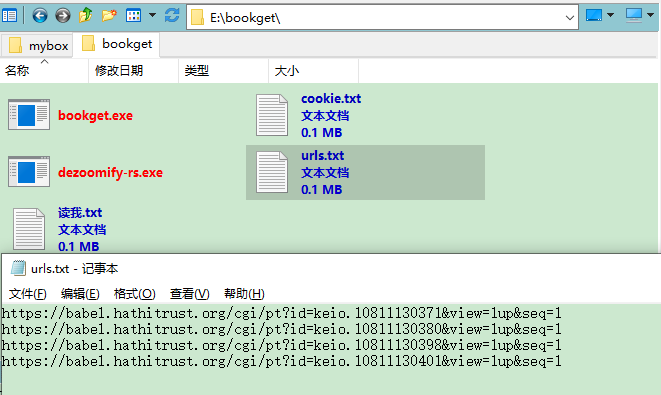
离成功只差一步,以下两种方法,你任选其一。
1、执行以下命令,下载的文件会在E盘目录下:
bookget -i e:\bookget\urls.txt2、执行以下命令,下载的文件在E:\bookget目录下:
cd bookget bookget -i urls.txt
轩辕十四游客@zhudw #89435
学到了,尝试2个方法都成功了!
链接:https://pan.baidu.com/s/1zZKiPqjgb8DAc814Nw5Y3Q?pwd=df4c
提取码:df4c多谢先生解惑!
不知有汉游客zhudw大神您好,请教一下familysearch网站现在怎么下载啊??已经按照香港中文大学的情况配置了cookie,然后在familysearch网站检索某本家谱,点击“检视图像”后出现新页面,在bookget里面输入这个新页面的链接,没法下载,请问是什么问题呢??我看了一下似乎是那个新页面的链接格式不对,那请问应该如何下载呢??
桐桐游客@zhudw #89424
我浙江古籍的不知道为什么下不了,可能也和我电脑有关系,手机和微信里面能打开网址,但是电脑浏览器打不开
古话游客bookget v1.1.3 版本无法下载普林斯顿大学图书,测试链接如下:
以正游客请教一下:最新版如何设置从国图下载的书现实中文名,我在《读我》文件里面看到这句:“ 保存文件名规则。可选值[0|1]。0=中文名,1=数字名。仅对 read.nlc.cn 有效。”不知具体如何操作,默认是现实数字名的。
zhudw游客
guhua游客
zhudw游客@guhua #89605
这些不是问题,不影响,你可以试试手动下载显示的图片网页。
进无止境游客@zhudw #89612
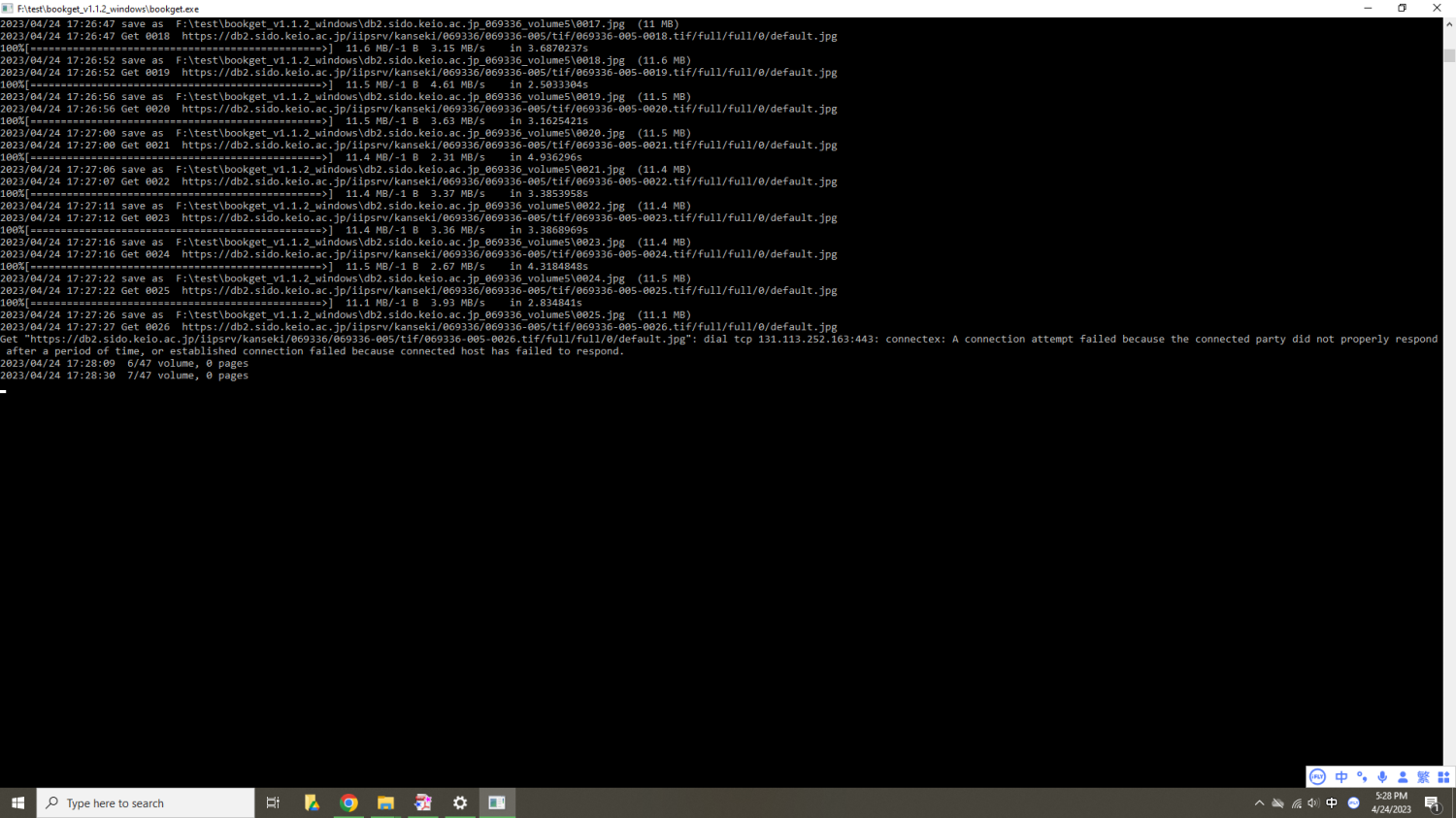
您好,请教您一下,我用最新的1.1.3版本下载香港中文大学的书籍出现了这样的提示,是哪里没有设置对吗?
书缘2022游客非常感谢zhudw兄共享这个软件,太好用了,运行也很稳定。不到一个月我就把国图两万多种古籍给盘下来了
进无止境游客@zhudw #89730
可以下载了,一下子就找到了问题所在,太感谢了!
一舟游客
金剛錘游客@zhudw #89575
來自一個窮逼精神和手動鍵盤的感謝,由衷的感謝,等我Python學成了我也搞搞
Bjuan游客正在试图用bookget 下载日本宫内厅书陵部收藏的群书治要手抄本,下载了几十页就无法连接了,再尝试连接,bookget 会显示 “ dialing to the given TCP address timed out”。 请问有没有其他的同修遇到这样的情况?有没有什么处理的方法?谢谢指点!
昌阳王游客您好,非常感谢您的软件,我水平太低,看了半天教程,实在搞不明白,只能来麻烦您了。
请问familysearch到底如何下载?我下载只建了一个文件夹,啥也没有,有没有更新的详版的使用说明?
zhudw游客
cycycy01游客版主好!win7 32位系统装不了啊!能解决吗?谢谢!
xiaopengyou游客@cycycy01 #90164
解決之道應該是要系統升級了,LZ的bookget神器是基於64位元開發的。
feng游客日本国立国会图书馆下载一本书,下载第二本的时候就下不了。
Bjuan游客@zhudw #90073
謝謝您! 我按照您說的方法換了个時間又嘗試了一下,可以繼續下載了,我自己規劃好時間,可以一次接著一次最終下載完成的。感謝開發這個軟件並且分享給我們!
可以看到群書治要的這個版本覺得不容易。感恩群主@未曾 #80139建的這個書格平臺。
xiaopengyou游客
墨雲游客@zhudw #89575
话说新版的bookget有办法利用代理的网络吗
我在cmd用了下列的命令,感觉还是没有变化,没法连上需要代理的其他网站,用旧版0.2.6的打开好像就能利用上了
set http_proxy=http://127.0.0.1:51942
set https_proxy=http://127.0.0.1:51942
未曾管理员@墨雲 #90252
你把这个存为bat文件到bookget同级目录试试(如果设置了环境变量则不需要)
@echo off set http_proxy=http://127.0.0.1:51942 set https_proxy=http://127.0.0.1:51942 bookget pause
读书人游客能否增加(恢复)初版的拖放功能,会方便很多,例如:在bookget根目录建立一个url.txt,将这个txt拖进exe就可以开始下载,记得以前是可以的,现在拖放没有反应
墨雲游客@未曾 #90258
不行,把端口改成我代理的端口也一样
墨雲游客@未曾 #90258
虽然先生以前教过类似的应用在dezoomify-rs的版本,但我电脑dezoomify-rs不加这个,所用网络也能随浏览器代理变化,旧版也同样没问题,但新版的bookget不行,对需要代理的网址开关代理都没反应,旧版是开关的下载反应不同的
- 作者帖子

 ,还是无法下载,请教下“urls.txt”正确的使用方法。。(环境变量已新建E)
,还是无法下载,请教下“urls.txt”正确的使用方法。。(环境变量已新建E)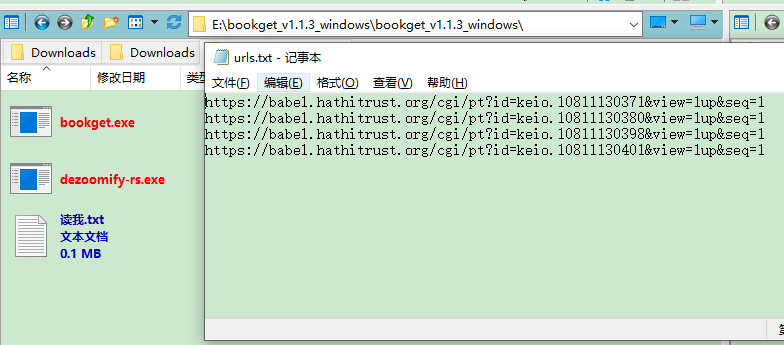

 请问familysearch到底如何下载?我下载只建了一个文件夹,啥也没有,有没有更新的详版的使用说明?
请问familysearch到底如何下载?我下载只建了一个文件夹,啥也没有,有没有更新的详版的使用说明?