标签: 优质分享
- 作者帖子

xiaopengyou游客@xiaopengyou #88316
把客服誤寫成客戶,抱歉!
自性若悟游客@xiaopengyou #88316
谁都是从小白过来的,你以前也提问过求教过,不知道现在为什么会说出这样的话,LZ也是为了帮助更多的人,你既然会也可以为其他小白分忧,既然不想帮助又何必在此说这种话?
自性若悟游客@zhudw #88277
兄好,根据您的指点我现在的方法是下载两次,一次下载整数的,一次下载-1的,是不是无法将两个一起整合下载呢
digicoll.lib.berkeley.edu/recor...009)_1.jpg

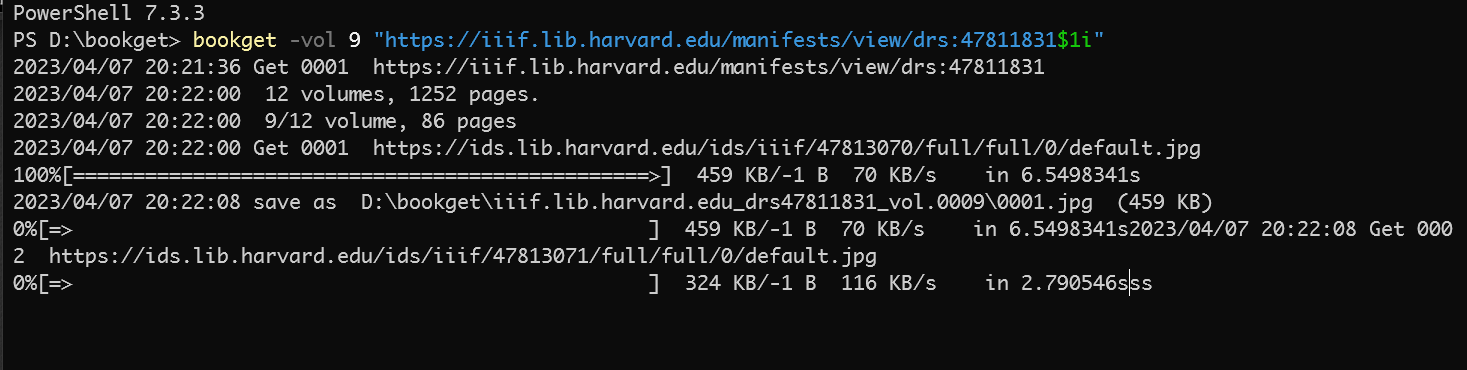
renyi游客請問我下載https://iiif.lib.harvard.edu/manifests/view/drs:47811831$1i這個連接時,無法下載第九卷,選了卷標-vol=9 依然是下載第一卷 請問什麼原因
renyi游客只下载部分页面功能好像不生效了,我是從1.09到1.11的,1.09可以選頁碼,1.11選了頁碼也會繼續往後下
xiaopengyou游客@自性若悟 #88319
我主要意思就是尊重LZ,這是他的地盤他做主,但既然您@我,我就說說:
在bookget的九個歐美數字圖書館,並沒有伯克利大學啊,朋友不就是把LZ當客服嗎?
按版規,您的問題不屬於bookget專區,LZ可不回應,但他還是回應了,不是嗎?
自性若悟游客@xiaopengyou #88324
我对这类的电脑操作真的是不太懂,我从关注书阁网站学到了很多的知识,虽然只是你们认为的皮毛,从最早的未曾先生的帮助,到现在的zhudw先生的帮忙,让我从中学到了很多基础知识。我从这个帖子的回复中一点点的尝试,有时候回复中没有实在不知道怎么办了才询问,经过LZ的指点我也成功的下载到了基本书籍。人生不就是慢慢的学习积累吗?来这个网站不也是互相交流学习帮助吗?你可以高高在上的去鄙视小白,更可可以冷眼旁观,没有人说你有义务去帮助别人,但是帮忙的人被你说成客服?这就是你所谓的尊重吗?勿以恶小而为之,勿以善小而不为
zhudw游客居然吵起来啦,楼上的问题我稍后回复。
可能大家对于 github 程序员的世界不了解。在 github 上的企业开源项目是不接受捐赠的,个人项目却是有的开通了捐赠。细心的朋友可以关注一些星星超过 1K 的项目,可能会有Sponsor(粉色)按钮,大概这种功能是要很多星星才有权申请,你们也没给我点赞,才几颗星星,我也不清楚,哈哈哈。
bookget 接受捐赠有以下原因:
1、软件开源,免费。人力成本不能是免费,人的生命和时间是宝贵的,因此在这方面,我表达的不是技术或者知识付费,而是人工成本。开源,不等于驱使他人免费劳动。
2、是近期我的生活发生了一些变故,导致我对人性很失望,尤其是某个医生,毫无节操,没有人品,简直是社会的人渣。个人私事不想再说,甚至影响到我的人生观。
开发者不是客服,有些人不看教程,不学习就说不会,不愿意花时间,伸手就要。这不是一个好现象,消耗的是我的精力。如果都这样子,干脆教程都不写了😂
最后说一句:
知识付费体现的是劳动力合理的价值回报。我没有要求大家使用软件付费,您只要不驱使我劳动,随便您怎么用,您甚至可以出售该软件获利,都是在 GPLv3 许可证范围以内的事。
我作为一个书格网友,和大家之间是平等的。
zhudw游客
zhudw游客
自性若悟游客@zhudw #88332
首先很感激先生对我的帮助知道,我已经很受用了,只是对专业知识的确实,可能问了些很简单没有难度的问题,以后一定多多学习,可能刚才没有太注意xiaopengyou网友所表达的意思,有些情绪化了,抱歉。
关于伯克利大学的问题,既然有版规要求,那先生也别在意了,我所需不多,简单下载一些就够了,不必费心了,对于以后的提问我会思量再三,同时多向各位前辈老师学习,再次谢谢先生的帮助,也祝您万事顺心!
吃饺子不沾醋游客@自性若悟 #88334
伯克利的那个可以直接下载
自性若悟游客@吃饺子不沾醋 #88338
是能直接下载,一张张的太慢了
zhudw游客@renyi #88323
补充一下:页面范围seq试一下1.1.2版
光游客古语云为人父母者不知医,谓不慈;为人子女者不知医,谓不孝。医者仁心!德技立身!缺一不可!所以一直建议全民学习中医!让每个人都能自由地看到好的中医书!
道统游客@zhudw #82347
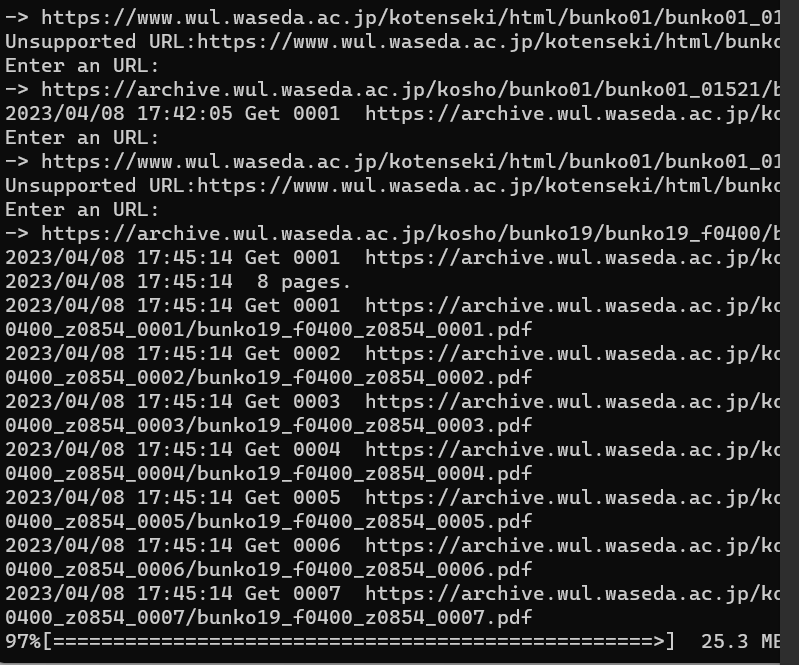
先生你好 在下载早稻田的时候出现了在一个文件夹内反复覆盖的情况不知道怎么解决https://archive.wul.waseda.ac.jp/kosho/bunko19/bunko19_f0400/bunko19_f0400_z0854/
archive.wul.waseda.ac.jp/kosho...400_z0855/
archive.wul.waseda.ac.jp/kosho...400_z0856/
archive.wul.waseda.ac.jp/kosho...400_z0857/
archive.wul.waseda.ac.jp/kosho...400_z0858/
archive.wul.waseda.ac.jp/kosho...400_z0859/
xiaopengyou游客@道统 #88407
如果還沒得到技術解決bookget,又想批量下載早稻田的資源,您可以觀察每個 PDF的URL是不是有規律?有規律,您就可以用IDM或motrix批量下載了。
這兩種下載工具的方法,交流區也都有,只是IDM只有一個月的免費期。
或供參考
吃饺子不沾醋游客@自性若悟 #88344
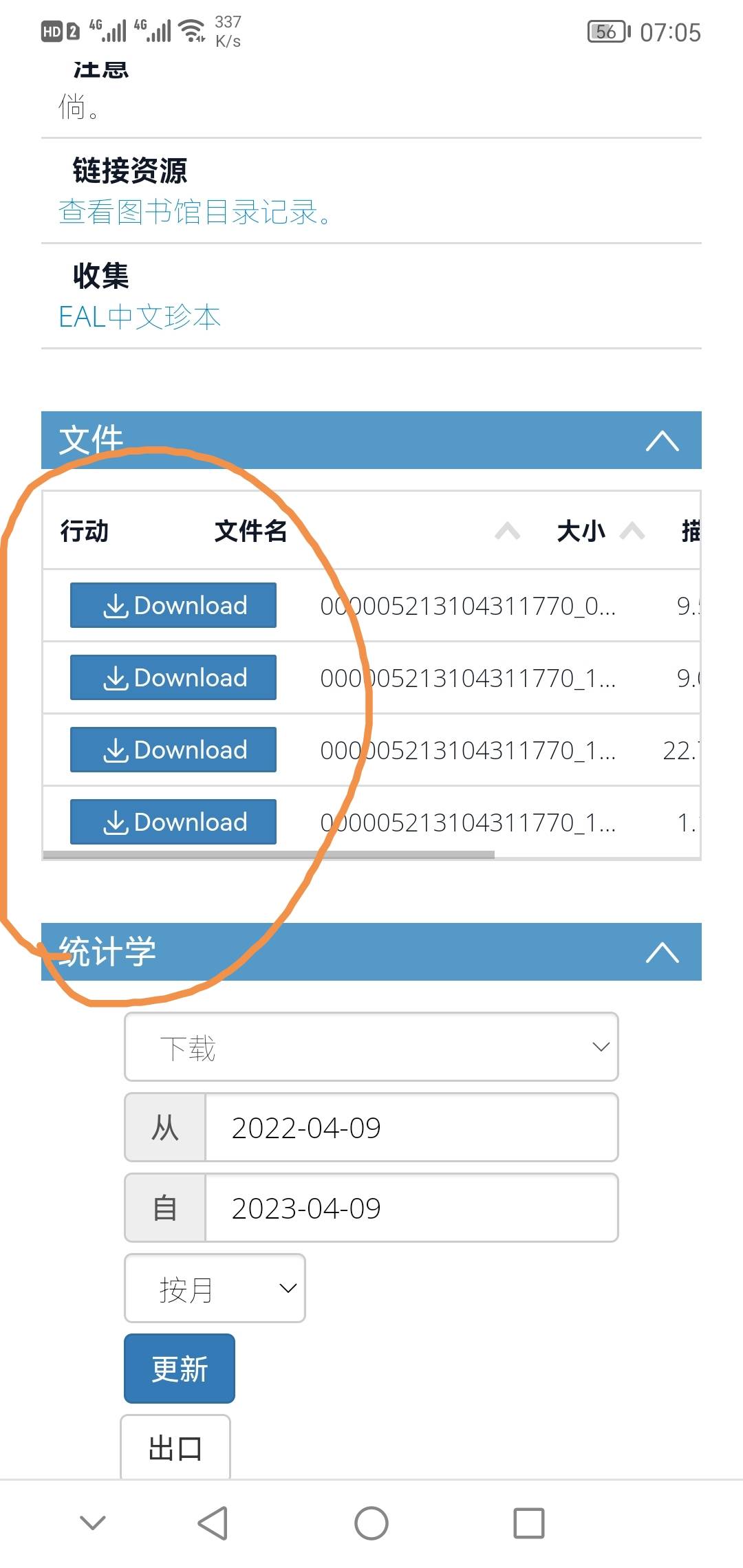
单册整本下载的图中画圈的 蓝色下载英文点击就可下载,再不就是复制链接用批量软件下载
无意游客各位好,有谁知道现在点击bookget为啥没反应(不运行)?谢谢。
无意游客问题已解决。是本人电脑掉线了。抱歉
zhudw游客@道统 #88407
修改了一下,试一下这个版本:github.com/dewei...tag/v1.1.2
默认下载jpg图片,如需下载pdf。使用以下命令行参数(任选一种):
bookget -ext=.pdf bookget -ext=.pdf "http://..." bookget -ext=.pdf -i urls.txt
haha游客@zhudw #88452
运行这个参数,下的好像还是jpg啊
zhudw游客
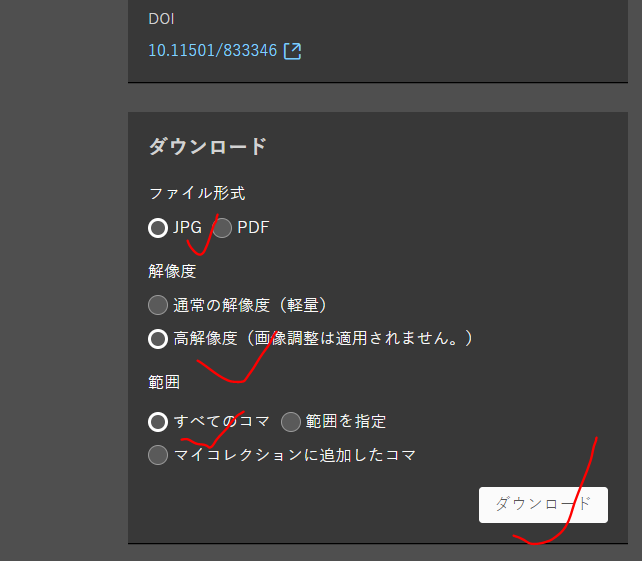
未学游客国立国会有很多书是没有iiif链接的,譬如https://dl.ndl.go.jp/pid/833346/1/1,望版主有空研究一下看看有没有办法下载,谢谢!
zhudw游客
fanyan1026游客故宫下载图片流程
“逛商场模式”:①在网站上挑选自己需要的或者喜欢的作品的图片链接,并放入txt文件,②使用py代码批量获取下载链接(代码我放在下面),③用Excel排序一下txt中的地址,然后覆盖(因为获取的链接有重复的,还有py打印的类别有空行,处理之后相连的图片会混乱,图片多了不好归类)④然后使用管理员的alldown批处理启动de下载
import os,sys,time,json,time import socket,random,hashlib import requests,configparser import json,re from datetime import datetime from multiprocessing.dummy import Pool as ThreadPool import urllib.request urllist = [] with open("piclink.txt","r") as f: for line in f.readlines(): line = line.replace("\n","") urllist.append(line) f.close() print("图片页面链接已读取") i = 0 for iurl in urllist: html = requests.get(iurl).text pic_url = re.findall('custom_tilegenerator="(.*?)"',html,re.S) for key in pic_url: log = open("log.txt", mode = "a+", encoding = "utf-8") print(key + "\r\n") print(key + "\r\n",file = log) i +=1 log.close() print("deep zoom Image 链接获取完毕,并保存print内容到log") print("dezoomify-rs下载链接修改中......") search_text = "/dyx.html?path=" replace_text = "" with open(r'log.txt', 'r',encoding='UTF-8') as file: data = file.read() data = data.replace(search_text, replace_text) print("dezoomify-rs下载链接修改完毕!!!") with open(r'urls1.txt', 'w',encoding='UTF-8') as file: file.write(data) with open(r'urls1.txt', 'r', encoding='utf-8') as f: listNet = f.readlines() print(f"去重前数量:{len(listNet)}") listNet = [x.strip() for x in listNet] listNet = [x.strip() for x in listNet if x.strip() != ''] print(f"去除空行后数量:{len(listNet)}") listNet = list(set(listNet)) print(f"去重后数量:{len(listNet)}") with open(r'urls.txt', 'w', encoding='utf-8') as f2: for i in range(len(listNet)): listNet[i] = listNet[i] + '\n' f2.writelines(listNet) f.close() os.remove('urls1.txt') os.remove('log.txt') print("保存deep zoom Image链接到urls.txt完毕")代码比较简陋,自己摸索瞎搞的,下载时候错误的自己看下载是的列表情况 重新手动,或者我分享的一个小工具可以直接下载
有能力的可以丰富一下功能,比如自己获取一类作品的链接,这样就不用自己找图片链接了,其次加入代理功能,台湾故宫的应该也可以这样获取(get的命令可能不一样,前天我自己测试了下 代理 好像可以用,但是台湾故宫的上不去,要么是代理问题,要么获取的方式不对)
直接使用爬取软件获取链接的话会有漏掉的和出错的
中华珍宝馆下载 我从网上找到一个py获取pdf格式大图的代码 可以使用 但是只能一个一个来
"""
by Polygon
tip: execjs => pip install PyExecJs
support
第一代:(不再支持)
www.ltfc.net/img/6...759889243b
cag.ltfc.net/cagst...t=639fa980
第二代:
g2.ltfc.net/view/...4a09d1665a
g2.ltfc.net/view/...d2f4023c07updated 2021-12-27
"""
from threading import Thread
from queue import Queue
from PIL import Image
import requests
import execjs
import time
import math
import re
import osclass ParsePDF:
"""
mode: 输出格式
quality: 18原画,每减1,画质损失一半
threadCount: 下载拼图线程数,值越大越快
tileSize: 不要修改
"""
mode = 'pdf'
quality = 18
threadCount = 16
tileSize = 512
finish = 0def __init__(self, kwargs):
"""
kwargs:
title
uuid
totalWidth
totalHeight
"""
# 更新参数for k, v in kwargs.items(): self.__dict__[k] = v self.totalWidth = int(self.totalWidth / 2**(18 - self.quality)) self.totalHeight = int(self.totalHeight / 2**(18 - self.quality)) if min(self.totalHeight, self.totalWidth) < self.tileSize: raise ValueError(f'{self.quality} value of a is too small') print(f'{self.title} | totalWidth={self.totalWidth} | totalHeight={self.totalHeight}') # 创建文件夹 self.root = os.path.join(self.root, self.title) if not os.path.exists(self.root): os.makedirs(self.root) # 下载 self.urlQueue = Queue() self.fileQueue = Queue() self.downloadImages() def printState(self): self.isFinished = False self.downloading = '' self.merging = '' while not self.isFinished: if self.downloading and self.merging: self.downloading.split('.')[0].split('_') percent = self.finish / self.total * 100 if self.finish == self.total: self.fileQueue.put(False) print(f'\r{percent:.2f}% | downloading {self.downloading} | merging {self.merging}' + ' ' * 20, end='') def encodeImageURL(self, baseURL): t = hex(int(31536e3 * int(math.ceil(time.time() * 1000 / 31536e6))))[2:] reg = "^(http.*\/\/[^\/]*)(\/.*\.(jpg|jpeg))\?*(.*)$" res = re.match(reg, baseURL) host, path, param = res.group(1), res.group(2), res.group(4) baseURL = self.cag_host + path + t imageURL = ''.join([host, path, "?", param, "&sign=", self.cag(baseURL), "&t=", t]) return imageURL def save(self): base = 'https://cag.ltfc.net/cagstore/' + self.uuid + '/' + str(self.quality) + '/{}_{}.jpg' while not self.urlQueue.empty(): column, row = self.urlQueue.get() baseURL = base.format(column, row) imageURL = self.encodeImageURL(baseURL) filename = re.findall('/(\d+_\d+\.(jpg|jpeg))\?', imageURL)[0][0] self.downloading = filename try: res = requests.get(imageURL) if res.headers['Content-Type'] in ['application/json', 'text/html']: print('requests imageURL fail') continue with open(os.path.join(self.root, filename), 'wb') as f: f.write(res.content) self.fileQueue.put(filename) except: self.urlQueue.put((column, row)) def downloadImages(self): columnCount, rowCount = math.ceil(self.totalWidth / self.tileSize), math.ceil(self.totalHeight / self.tileSize) self.total = columnCount * rowCount Thread(target=self.mergeImages).start() Thread(target=self.printState).start() self.cag_host = re.findall('"([0-9a-z]{40})"', requests.get('http://cdn-a.ltfc.net/js/cag_1639995681989_min.js').text)[0] for column in range(columnCount): for row in range(rowCount): self.urlQueue.put((column, row)) for _ in range(self.threadCount): Thread(target=self.save).start() def mergeImages(self): to_image = Image.new('RGB', (self.totalWidth, self.totalHeight)) while True: file = self.fileQueue.get() if not file: break self.merging = file column, row = list(map(int, file.split('.')[0].split('_'))) filepath = os.path.join(self.root, file) from_image = Image.open(filepath) to_image.paste(from_image, (column * self.tileSize, row * self.tileSize)) os.remove(filepath) self.finish += 1 self.isFinished = True print('\nwrite to local...') filepath = os.path.join(self.root, f'{self.title}.{self.mode}') to_image.save(filepath) print(f'success | {filepath}') os.startfile(filepath) @staticmethod def cag(s): jsStr = """ function cagcycle(t, e) { var n = ff(n = t[0], s = t[1], r = t[2], i = t[3], e[0], 7, -680876936) , i = ff(i, n, s, r, e[1], 12, -389564586) , r = ff(r, i, n, s, e[2], 17, 606105819) , s = ff(s, r, i, n, e[3], 22, -1044525330); n = ff(n, s, r, i, e[4], 7, -176418897), i = ff(i, n, s, r, e[5], 12, 1200080426), r = ff(r, i, n, s, e[6], 17, -1473231341), s = ff(s, r, i, n, e[7], 22, -45705983), n = ff(n, s, r, i, e[8], 7, 1770035416), i = ff(i, n, s, r, e[9], 12, -1958414417), r = ff(r, i, n, s, e[10], 17, -42063), s = ff(s, r, i, n, e[11], 22, -1990404162), n = ff(n, s, r, i, e[12], 7, 1804603682), i = ff(i, n, s, r, e[13], 12, -40341101), r = ff(r, i, n, s, e[14], 17, -1502002290), n = gg(n, s = ff(s, r, i, n, e[15], 22, 1236535329), r, i, e[1], 5, -165796510), i = gg(i, n, s, r, e[6], 9, -1069501632), r = gg(r, i, n, s, e[11], 14, 643717713), s = gg(s, r, i, n, e[0], 20, -373897302), n = gg(n, s, r, i, e[5], 5, -701558691), i = gg(i, n, s, r, e[10], 9, 38016083), r = gg(r, i, n, s, e[15], 14, -660478335), s = gg(s, r, i, n, e[4], 20, -405537848), n = gg(n, s, r, i, e[9], 5, 568446438), i = gg(i, n, s, r, e[14], 9, -1019803690), r = gg(r, i, n, s, e[3], 14, -187363961), s = gg(s, r, i, n, e[8], 20, 1163531501), n = gg(n, s, r, i, e[13], 5, -1444681467), i = gg(i, n, s, r, e[2], 9, -51403784), r = gg(r, i, n, s, e[7], 14, 1735328473), n = hh(n, s = gg(s, r, i, n, e[12], 20, -1926607734), r, i, e[5], 4, -378558), i = hh(i, n, s, r, e[8], 11, -2022574463), r = hh(r, i, n, s, e[11], 16, 1839030562), s = hh(s, r, i, n, e[14], 23, -35309556), n = hh(n, s, r, i, e[1], 4, -1530992060), i = hh(i, n, s, r, e[4], 11, 1272893353), r = hh(r, i, n, s, e[7], 16, -155497632), s = hh(s, r, i, n, e[10], 23, -1094730640), n = hh(n, s, r, i, e[13], 4, 681279174), i = hh(i, n, s, r, e[0], 11, -358537222), r = hh(r, i, n, s, e[3], 16, -722521979), s = hh(s, r, i, n, e[6], 23, 76029189), n = hh(n, s, r, i, e[9], 4, -640364487), i = hh(i, n, s, r, e[12], 11, -421815835), r = hh(r, i, n, s, e[15], 16, 530742520), n = ii(n, s = hh(s, r, i, n, e[2], 23, -995338651), r, i, e[0], 6, -198630844), i = ii(i, n, s, r, e[7], 10, 1126891415), r = ii(r, i, n, s, e[14], 15, -1416354905), s = ii(s, r, i, n, e[5], 21, -57434055), n = ii(n, s, r, i, e[12], 6, 1700485571), i = ii(i, n, s, r, e[3], 10, -1894986606), r = ii(r, i, n, s, e[10], 15, -1051523), s = ii(s, r, i, n, e[1], 21, -2054922799), n = ii(n, s, r, i, e[8], 6, 1873313359), i = ii(i, n, s, r, e[15], 10, -30611744), r = ii(r, i, n, s, e[6], 15, -1560198380), s = ii(s, r, i, n, e[13], 21, 1309151649), n = ii(n, s, r, i, e[4], 6, -145523070), i = ii(i, n, s, r, e[11], 10, -1120210379), r = ii(r, i, n, s, e[2], 15, 718787259), s = ii(s, r, i, n, e[9], 21, -343485551), t[0] = add32(n, t[0]), t[1] = add32(s, t[1]), t[2] = add32(r, t[2]), t[3] = add32(i, t[3]) } function cmn(t, e, n, i, r, s) { return e = add32(add32(e, t), add32(i, s)), add32(e << r | e >>> 32 - r, n) } function ff(t, e, n, i, r, s, o) { return cmn(e & n | ~e & i, t, e, r, s, o) } function gg(t, e, n, i, r, s, o) { return cmn(e & i | n & ~i, t, e, r, s, o) } function hh(t, e, n, i, r, s, o) { return cmn(e ^ n ^ i, t, e, r, s, o) } function ii(t, e, n, i, r, s, o) { return cmn(n ^ (e | ~i), t, e, r, s, o) } function cag1(t) { txt = ""; for (var e = t.length, n = [1732584193, -271733879, -1732584194, 271733878], i = 64; i <= t.length; i += 64) cagcycle(n, cagblk(t.substring(i - 64, i))); t = t.substring(i - 64); var r = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]; for (i = 0; i < t.length; i++) r[i >> 2] |= t.charCodeAt(i) << (i % 4 << 3); if (r[i >> 2] |= 128 << (i % 4 << 3), 55 < i) for (cagcycle(n, r), i = 0; i < 16; i++) r[i] = 0; return r[14] = 8 * e, cagcycle(n, r), n } function cagblk(t) { for (var e = [], n = 0; n < 64; n += 4) e[n >> 2] = t.charCodeAt(n) + (t.charCodeAt(n + 1) << 8) + (t.charCodeAt(n + 2) << 16) + (t.charCodeAt(n + 3) << 24); return e } var hex_chr = "0123456789abcdef".split(""); function rhex(t) { for (var e = "", n = 0; n < 4; n++) e += hex_chr[t >> 8 * n + 4 & 15] + hex_chr[t >> 8 * n & 15]; return e } function hex(t) { for (var e = 0; e < t.length; e++) t[e] = rhex(t[e]); return t.join("") } function cag(t) { return hex(cag1(t)) } function add32(t, e) { return t + e & 4294967295 } { function add32(t, e) { var n = (65535 & t) + (65535 & e); return (t >> 16) + (e >> 16) + (n >> 16) << 16 | 65535 & n } cag("hello") } """ js = execjs.compile(jsStr) return js.call('cag', s) if __name__ == "__main__": root = 'pdf' url = 'http://g2.ltfc.net/view/SUHA/608a61aeaa7c385c8d944403' if 'g2.ltfc.net' in url: # 第二代网页 method, Id = re.findall('/([A-Z]+)/(\w{24})', url)[0] res = requests.post('https://api.quanku.art/cag2.TouristService/getAccessToken') token = res.json()['token'] res = requests.post(f'https://api.quanku.art/cag2.{method.lower().capitalize()}Service/get', json={"Id": Id, "context":{"tourToken": token}}) data = res.json() Id = data['hdp']['id'] title = data['name'] if 'name' in data else data['title'] if data['hdp']['src'] == 'COLL': # 多张 res = requests.post('https://api.quanku.art/cag2.HDPicService/getHDPicOfColl', json={'Id': Id}) for i, item in enumerate(res.json()['data'], 1): print(f'\n第{i}副') ParsePDF({ 'root': os.path.join(root, title), 'title': os.path.splitext(item['title'])[0], 'uuid': item['resourceId'], 'totalWidth': item['size']['width'], 'totalHeight': item['size']['height'] }) else: # 单张 uuid = re.findall('\w{24}', res.json()['snapUrl'])[0] res = requests.post('https://api.quanku.art/cag2.HDPicService/get', json={'Id': Id}) item = res.json() ParsePDF({ 'root': root, 'title': title, 'uuid': item['resourceId'], 'totalWidth': item['size']['width'], 'totalHeight': item['size']['height'] }) else: raise KeyError('暂不支持旧版')
kk游客@zhudw #88331
云南中医药大学古籍数字图书馆 伤寒广要 请老师试试看,能不能下载,为什么都是空文件。我发现,所有书名中间带点的,都是空文件。比如 伤寒广要(卷一·卷二) 卷一和卷二 中间的点,BOOKget 就不能下载。请老师看看什么情况。谢谢。
剔藓扫尘游客
艺游客@一舟 #82744
能分享1.05的下载链接吗?谢谢
兰亭幽梦游客@zhudw #88493
您好,我有个问题想问一下,弗利尔的长卷iiif图用这个软件能下载吗,反正用拼图不行。谢谢
xiaopengyou游客
兰亭幽梦游客@xiaopengyou #88614
故宫名画记可以,我就问一下弗利尔的能下载不,大神可以把弗利尔加入
青鹤游客@fanyan1026 #88535
程序员就是🐂,虽然我看不懂!😂
zhudw游客
牛博士后游客0.2.6版本图片教程看不懂,哪位老师能出个视频教程?只想下载犹他家谱网的家谱。谢谢啦。
一舟游客@牛博士后 #88718
去这里看指南:https://github.com/deweizhu/bookget/wiki 指南很详细的。
一舟游客@牛博士后 #88718
刚注意到,新版本不支持犹他家谱网了。真可惜。
kk游客@zhudw #88695
感谢老师
牛博士后游客@一舟 #88722
早看过啦,这不是看不懂嘛。
zhudw游客@一舟 #88722
familysearch家譜網,並非技術上不支持。你現在重下載一次1.1.2版是可以下載的。只是這個站問的人多,問題多,不想再解釋。
使用方法參考 wiki手冊中「09 香港中文大学图书馆」,編寫cookie.txt 可以下載家譜網。
期待視頻教程就有點奢侈了,圖文教程大概率都沒有人寫的。
牛博士后游客@zhudw #88746
先谢谢啦。晚上回去试试。
牛博士后游客@zhudw #88746
刚刚亲测成功了,正在下载中。谢谢大神。
天一生水游客云南数字方志馆http://dfz.yn.gov.cn/record/pdf?id=old160001
后缀是这样不规则的,请教大神如何批量下载?
yunnan-fangzhi-internal.yunnan-2.zos.ctyun.cn/file/...7x8IWYE%3D
yunnan-fangzhi-internal.yunnan-2.zos.ctyun.cn/file/...UCTtZs0%3D
天一生水游客@zhudw #88746
云南数字方志馆http://dfz.yn.gov.cn/record/pdf?id=old160001
后缀是这样不规则的,请教大神如何批量下载?
yunnan-fangzhi-internal.yunnan-2.zos.ctyun.cn/file/...7x8IWYE%3D
yunnan-fangzhi-internal.yunnan-2.zos.ctyun.cn/file/...UCTtZs0%3D
renyi游客请问一部书,下载完后,发现只有少数几页没下成功,比如4,125,668,1235,能否指定下这几页,而不是需要-seq=4:1235再遍历一遍
看书找书游客感谢,能否对新手讲下如何在移动设备最好还是苹果手机上使用这个软件~
zhudw游客
看书找书游客@zhudw #88830明白了,感谢~
zhudw游客@天一生水 #88805
云南方志是不能手动完成批量下载的。它存储在中国电信天翼云,每页查看或下载前,需要发起一次key验证。
国内网站涉及到下载,大多数都是违规窃取(他们的站点有防下载设计)。违规的事,我们不应该做,希望大家理解。基于这个层面的考虑,如果严格遵守道德标准,理应是删除所有大陆网站的。我可能,有一天会这么做。
你可以用1.1.2版试试能不能下载,或许有惊喜。
- 作者帖子